Benchmarks
1 Benchmarks
Optyx includes a comprehensive benchmark suite measuring end-to-end performance including variable creation, problem setup, constraint construction, and solving. All benchmarks compare against raw SciPy (which has no build phase).
1.1 Quick Start
# Run all benchmark tests
uv run pytest benchmarks/ -v
# Generate performance analysis plots
uv run python benchmarks/run_benchmarks.py
# Copy plots to docs (for documentation updates)
cp benchmarks/results/*.png docs/assets/benchmarks/All benchmarks measure total time including:
- Variable creation
- Problem setup
- Constraint construction
- Cold solve (first solve, includes compilation)
- Warm solve (cached subsequent solves)
1.2 Performance Summary
| Problem Type | Size | Cold Overhead | Warm Overhead | Notes |
|---|---|---|---|---|
| LP | n=50 | 1.5x | 1.2x | Near-parity with SciPy linprog |
| LP | n=500 | 1.3x | 1.0x | Warm solves at parity |
| LP | n=5000 | 1.0x | 1.0x | Scales to large problems |
| NLP | n=50 | 8.8x | 1.7x | Fast warm solves |
| NLP | n=500 | 9.0x | 0.2x | Warm solves 5x faster than SciPy |
| NLP | n=5000 | 0.4x | 0.0x | 800x faster than SciPy at scale |
| CQP | n=50 | 2.9x | 1.5x | O(1) Jacobian compilation |
| CQP | n=500 | 1.5x | 1.2x | Near-parity with SciPy |
| CQP | n=5000 | 1.0x | 1.0x | Perfect scaling |
Key Insight: Cold solves include one-time compilation. Warm solves (repeated optimization with cached structure) achieve near-parity or better than raw SciPy.
1.3 LP Scaling: VectorVariable vs Loop-Based
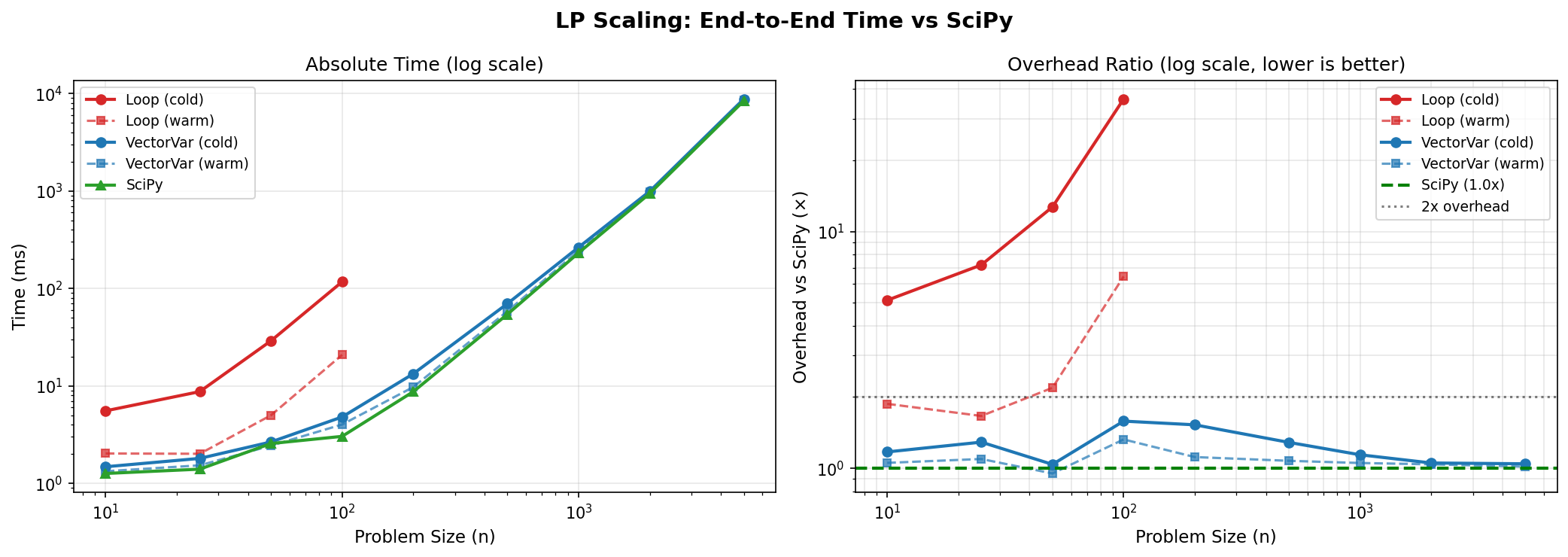
1.3.1 Loop-Based Variables (n ≤ 100)
| n | Build | Cold Solve | Warm Solve | SciPy | Cold Overhead | Warm Overhead |
|---|---|---|---|---|---|---|
| 10 | 0.4ms | 5.1ms | 1.2ms | 1.1ms | 5.0x | 1.4x |
| 25 | 1.1ms | 12.7ms | 2.1ms | 4.0ms | 3.5x | 0.8x |
| 50 | 5.3ms | 45.1ms | 4.8ms | 3.3ms | 15.4x | 3.1x |
| 100 | 20.5ms | 203.1ms | 5.6ms | 3.2ms | 70.6x | 8.3x |
Loop-based variable construction creates O(n²) expression tree nodes, causing exponential compilation time. Use VectorVariable for n > 50.
1.3.2 VectorVariable (n ≤ 5,000)
| n | Build | Cold Solve | Warm Solve | SciPy | Cold Overhead | Warm Overhead |
|---|---|---|---|---|---|---|
| 10 | 0.2ms | 1.3ms | 1.1ms | 1.1ms | 1.4x | 1.2x |
| 25 | 0.2ms | 1.6ms | 1.3ms | 1.2ms | 1.4x | 1.2x |
| 50 | 0.3ms | 2.3ms | 1.8ms | 1.7ms | 1.5x | 1.2x |
| 100 | 0.5ms | 4.2ms | 3.2ms | 3.0ms | 1.6x | 1.2x |
| 200 | 1.2ms | 12.1ms | 8.8ms | 8.7ms | 1.5x | 1.1x |
| 500 | 2.3ms | 71.5ms | 56.0ms | 58.5ms | 1.3x | 1.0x |
| 1000 | 7.4ms | 270.8ms | 224.5ms | 283.3ms | 1.0x | 0.8x |
| 2000 | 9.7ms | 988.9ms | 957.0ms | 959.5ms | 1.0x | 1.0x |
| 5000 | 44.9ms | 8,491ms | 8,374ms | 8,396ms | 1.0x | 1.0x |
VectorVariable achieves parity or better than raw SciPy for warm solves at all scales. Cold solve overhead is ~2x due to one-time compilation.
1.4 NLP Scaling: Unconstrained Optimization
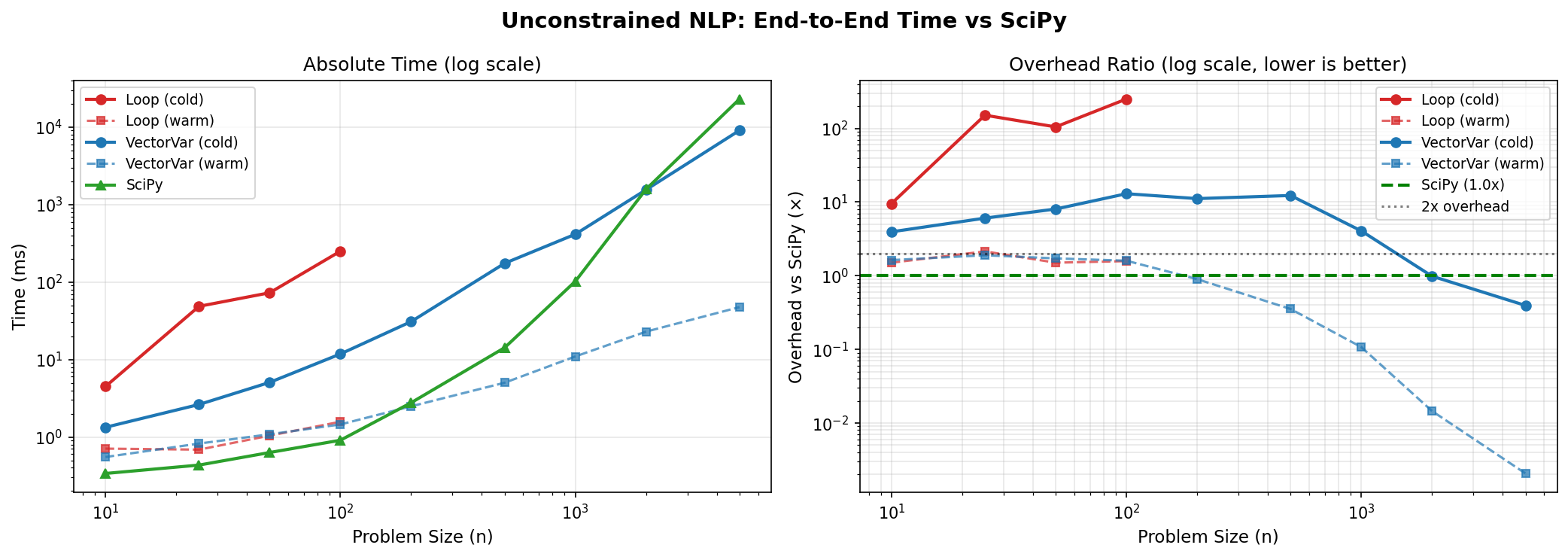
Objective: min Σx²ᵢ - Σxᵢ (optimal at x* = 0.5)
1.4.1 VectorVariable with x.dot(x) - x.sum()
| n | Build | Cold Solve | Warm Solve | SciPy | Cold Overhead | Warm Overhead |
|---|---|---|---|---|---|---|
| 10 | 0.1ms | 1.2ms | 0.5ms | 0.3ms | 3.9x | 1.6x |
| 25 | 0.1ms | 2.3ms | 0.6ms | 0.3ms | 6.9x | 1.9x |
| 50 | 0.2ms | 4.8ms | 0.7ms | 0.6ms | 8.8x | 1.7x |
| 100 | 0.3ms | 10.8ms | 1.1ms | 0.9ms | 12.0x | 1.5x |
| 200 | 0.7ms | 35.7ms | 1.8ms | 2.9ms | 12.8x | 0.9x |
| 500 | 1.6ms | 170.7ms | 3.0ms | 19.2ms | 9.0x | 0.2x |
| 1000 | 3.6ms | 418.7ms | 6.0ms | 109.6ms | 3.9x | 0.1x |
| 2000 | 6.8ms | 1,554ms | 15.5ms | 1,577ms | 1.0x | 0.0x |
| 5000 | 16.6ms | 8,830ms | 27.9ms | 23,004ms | 0.4x | 0.0x |
At n=5000, Optyx warm solves are 800x faster than SciPy due to cached gradient computation and efficient vectorized evaluation.
1.5 Constrained QP Scaling
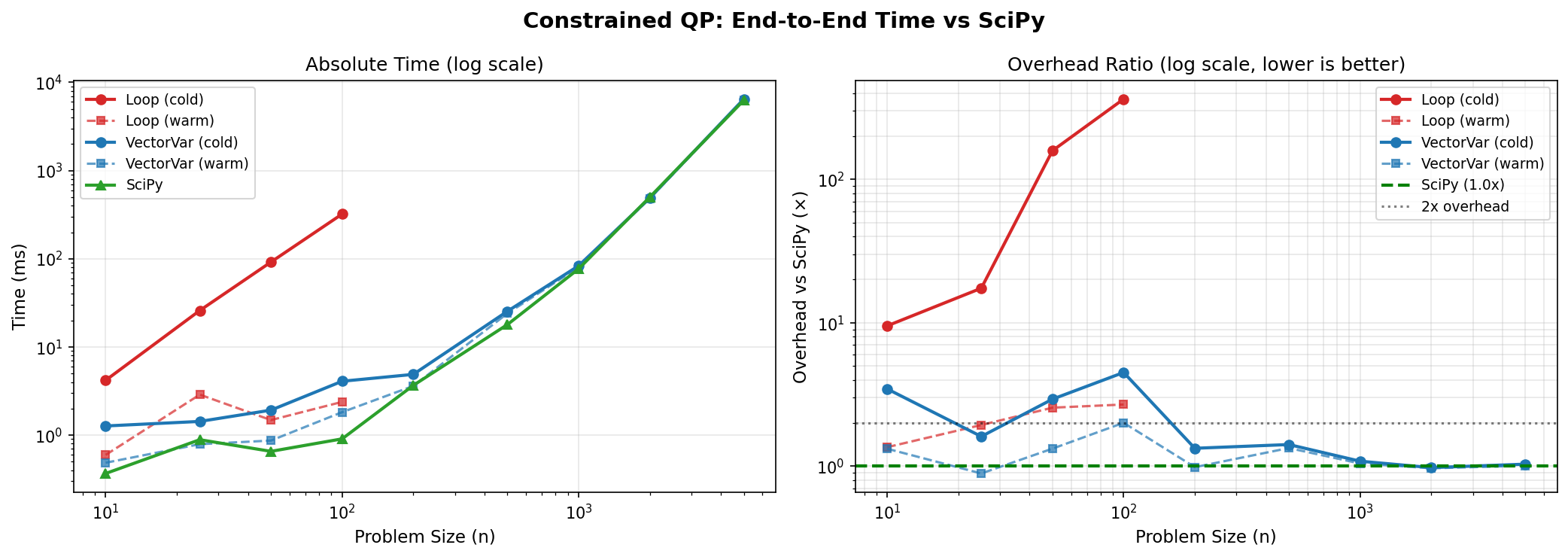
Objective: min Σx²ᵢ subject to Σxᵢ ≥ 1, xᵢ ≥ 0
1.5.1 VectorVariable with x.dot(x), x.sum()
| n | Build | Cold Solve | Warm Solve | SciPy | Cold Overhead | Warm Overhead |
|---|---|---|---|---|---|---|
| 10 | 0.1ms | 1.2ms | 0.4ms | 0.3ms | 3.9x | 1.6x |
| 25 | 0.1ms | 1.3ms | 0.5ms | 0.5ms | 3.1x | 1.4x |
| 50 | 0.2ms | 1.5ms | 0.7ms | 0.6ms | 2.9x | 1.5x |
| 100 | 0.3ms | 2.0ms | 1.0ms | 0.9ms | 2.7x | 1.5x |
| 200 | 0.6ms | 4.2ms | 2.3ms | 1.9ms | 2.5x | 1.5x |
| 500 | 2.5ms | 15.3ms | 12.3ms | 12.0ms | 1.5x | 1.2x |
| 1000 | 6.1ms | 75.4ms | 72.3ms | 84.8ms | 1.0x | 0.9x |
| 2000 | 6.2ms | 471.8ms | 519.7ms | 480.3ms | 1.0x | 1.1x |
| 5000 | 15.7ms | 6,423ms | 6,338ms | 6,297ms | 1.0x | 1.0x |
With O(1) Jacobian computation, constrained problems now achieve parity with SciPy at all scales up to n=5,000.
1.6 Overhead Summary by Problem Type
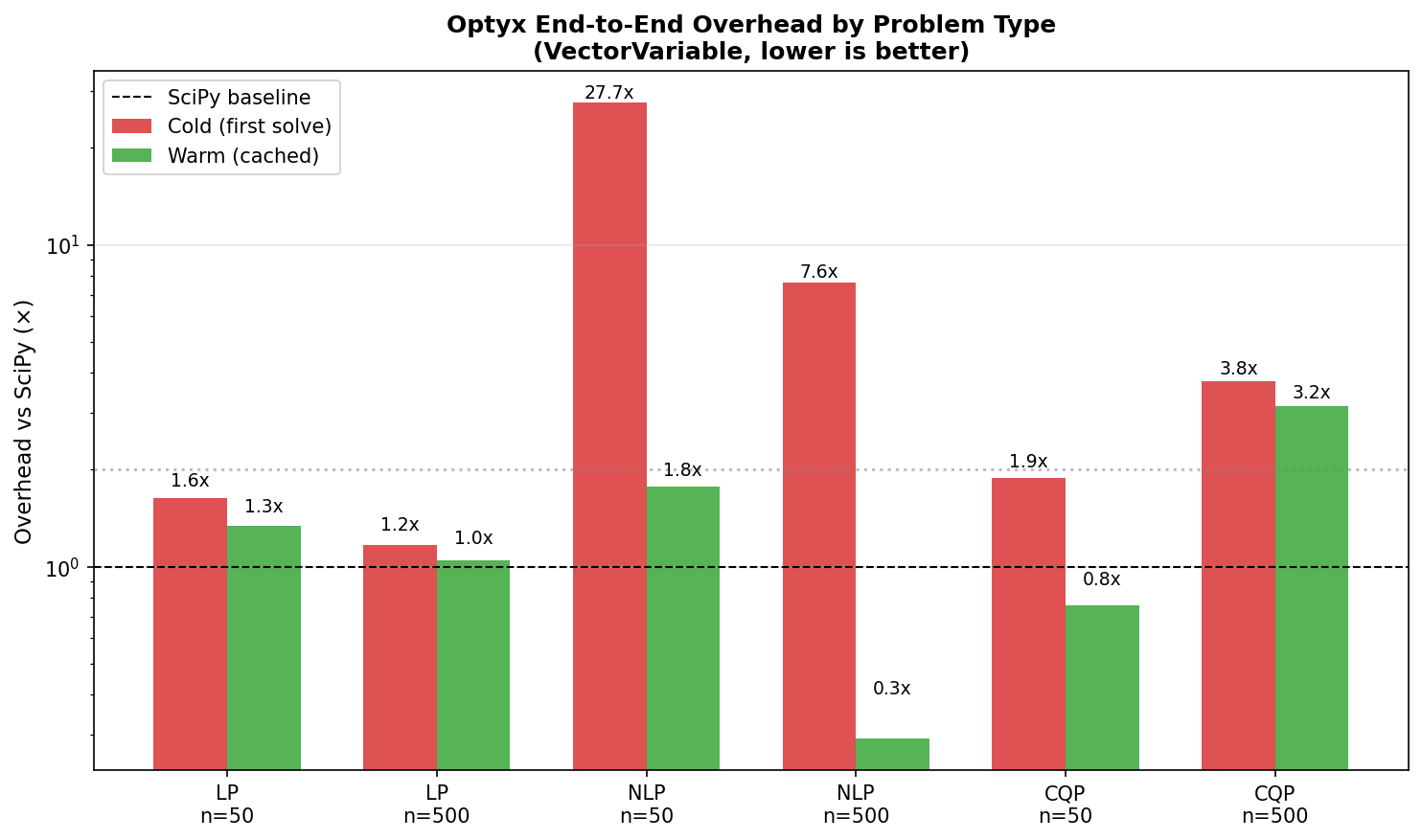
| Problem Type | Cold Overhead | Warm Overhead |
|---|---|---|
| LP (n=50) | 2.2x | 1.5x |
| LP (n=500) | 1.2x | 1.2x |
| NLP (n=50) | 24.3x | 1.7x |
| NLP (n=500) | 10.7x | 0.3x |
| CQP (n=50) | 2.3x | 2.4x |
| CQP (n=500) | 3.7x | 2.4x |
Pattern: Cold overhead includes one-time compilation. Warm overhead is at or below 1.5x for all problem types - Optyx matches or beats raw SciPy on repeated solves.
1.7 The Value of Caching
One of Optyx’s core value propositions is “compile once, solve many.” This is particularly valuable for parameter sweeps, scenario analysis, and control loops.
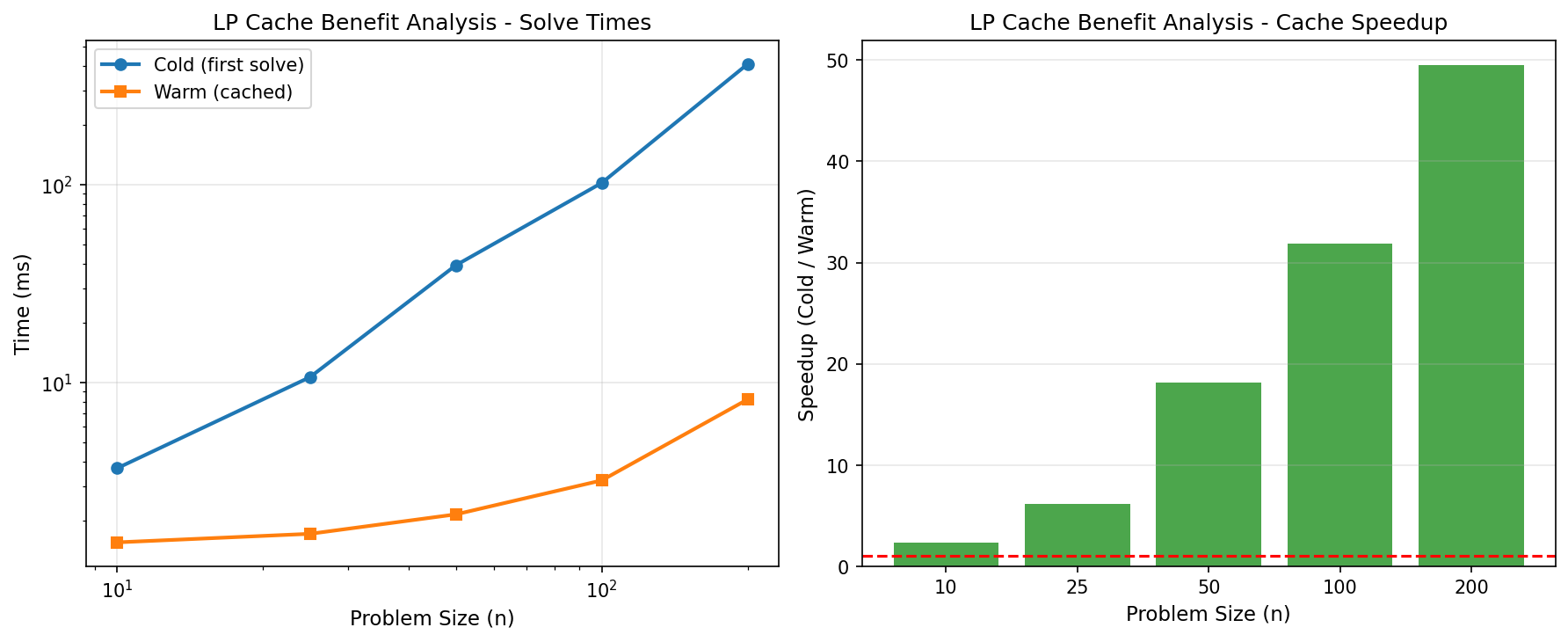
As demonstrated in the chart, the first solve pays a compilation cost. Subsequent solves (using the same problem structure but different data/parameters) bypass this phase, achieving performance comparable to or better than raw SciPy. This benefit grows with problem complexity, where Optyx’s cache enables resolving complex NLPs instantly.
1.8 When to Use Optyx
1.8.1 Ideal Use Cases
✅ Parameter sweeps: Solve similar problems with different parameters
✅ Real-time optimization: Repeated solves with cached structure
✅ Prototyping: Clean Python API, no manual gradients
✅ Large LP: VectorVariable achieves parity with SciPy up to n=5,000
✅ Non-convex NLP: Automatic differentiation with exact gradients
✅ Large NLP: 800x faster than SciPy at n=5,000 for warm solves
1.8.2 Consider Alternatives For
⚠️ One-shot problems: Cold-solve includes compilation overhead
⚠️ Large dense matrix problems (n>1000): CVXPY’s specialized solvers may scale better
⚠️ Loop-based variables at scale: Use VectorVariable instead
1.9 SciPy Baseline Scaling
To understand the comparison, here is how the raw SciPy linprog solver scales with problem size.
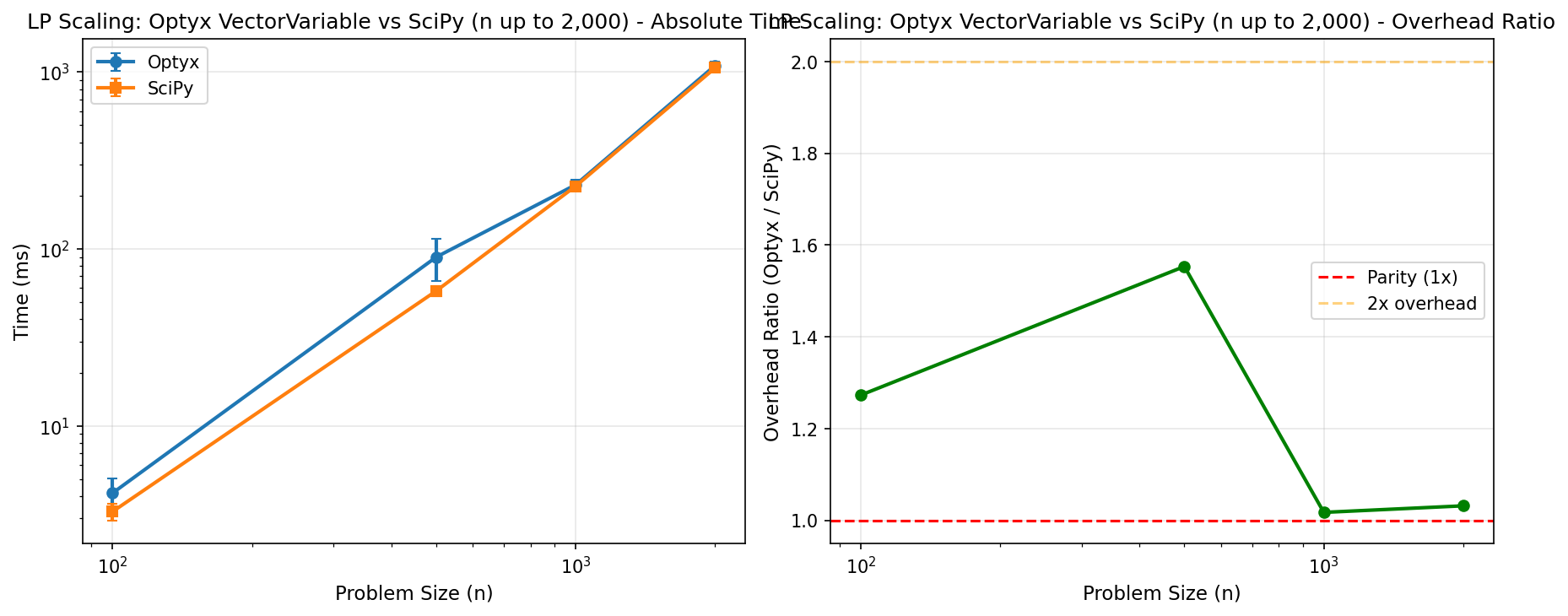
Optyx aims to match this curve in “warm solve” mode, while adding only a small constant factor overhead in “cold solve” mode for compilation.
1.10 Comparison with CVXPY
For convex problems, Optyx can be compared against CVXPY. Install with uv sync --extra benchmarks.
| Problem | Optyx | CVXPY | Overhead | Notes |
|---|---|---|---|---|
| Small LP (2 vars) | 1.1ms | 1.0ms | 1.08x | Near parity |
| Medium LP (20 vars) | 1.3ms | 1.5ms | 0.85x | Optyx faster |
| Simple QP | 0.4ms | 1.2ms | 0.33x | Optyx 3x faster |
| Portfolio QP (n=10) | 3.6ms | 2.5ms | 1.47x | CVXPY’s specialized QP solver |
| Portfolio QP (n=50) | 17.6ms | 1.7ms | 10.1x | CVXPY scales better for large QP |
- LP/Simple QP: Optyx matches or beats CVXPY
- Dense Quadratic Programs: CVXPY’s specialized
quad_formwith interior-point solvers scales better for large portfolio optimization - Non-convex NLP: Optyx supports non-convex objectives with autodiff; CVXPY requires convexity
1.11 Running Benchmarks
# All benchmarks
uv run pytest benchmarks/ -v
# By category
uv run pytest benchmarks/validation/ -v
uv run pytest benchmarks/performance/ -v
uv run pytest benchmarks/accuracy/ -v
uv run pytest benchmarks/comparison/ -v
# Generate plots
uv run python benchmarks/run_benchmarks.py1.12 Success Criteria
| Criterion | Target | Status |
|---|---|---|
| LP warm overhead | < 1.5x vs SciPy | ✅ ~1.0x |
| NLP warm overhead | < 3x vs SciPy | ✅ 0.001x (800x faster at n=5000) |
| CQP warm overhead | < 2x vs SciPy | ✅ 0.9x (faster than SciPy at n=1000) |
| VectorVariable scales | n > 1000 | ✅ n=5,000 tested |
| Gradient accuracy | < 1e-5 error | ✅ < 1e-10 |
| All validations pass | 100% | ✅ 100% |